



- 1. Консоль поиска Google:
- 2. Внешние инструменты:
- 3. «Сайт:» Оператор поиска:
- 1. Rel = «канонический»:
- Как мне это сделать?
- Что может пойти не так?
- 2. Хрефланг
- Как мне это сделать?
- Что может пойти не так?
- 3. 301 переадресация:
- 5. Консоль поиска Google:
- 6. Отслеживание хеш-тегов:
- 7. Содержимое по конкретным доменам доменов верхнего уровня:
- 8. Разбивка на страницы:
Часто в дискуссионных сообществах SEO встречаются вопросы от веб-мастеров, которые спрашивают: «Если я сделаю XYZ, повлечет ли это за дублирование контента?» Распространенное заблуждение, с тех пор, как Google выпустил обновление Panda, заключается в том, что существует штраф за дублирование контента, и вы рискуете удалить свой сайт из индекса Google, если у вас одинаковый контент на разных страницах вашего сайта. В какой-то момент во время создания контента вашего сайта вы могли подумать о дублировании контента; многократное использование одних и тех же изображений на сайте или, если это сайт электронной коммерции, беспокойство о том, что страницы категорий появляются в нескольких URL-адресах с одинаковым продуктом и описанием, или о том, что ваши статьи синдицированы дословно на других сайтах. места. Итак, сколько и о чем вам действительно нужно беспокоиться в отношении дублированного контента? Давайте начнем с основ.
Если вы не будете осторожны, вы можете случайно опубликовать дублированный контент несколькими различными способами:
Хорошей новостью является то, что есть некоторые методы на странице, которые вы можете использовать, чтобы избавиться от дублированного контента на вашем сайте. Они известны как rel = "canonical", hreflang и rel = "prev" / rel = "next" (нумерация страниц).
Любой контент, идентичный другому контенту, который существует либо на том же сайте, либо на другом.
Примеры:
- Содержимое вашего блога синдицировано (скопировано) на другой сайт.
- Если ваша домашняя страница имеет несколько URL-адресов, обслуживающих один и тот же контент, например: http://yoursite.com, http://www.yoursite.com и http://www.yoursite.com/index.htm.
- Страницы, которые были дублированы из-за идентификаторов сеансов и параметров URL, таких как http://yoursite.com/product и http://yoursite.com/product?sessionid=5486481.
- Страницы, которые имеют параметры сортировки на основе времени, даты, цвета или других критериев сортировки, могут создавать дубликаты страниц, такие как http://yoursite.com/category и http://yoursite.com/category?=sort=medium.
- Страницы с кодами отслеживания и аффилированными кодами, такими как http://yoursite.com/product и http://yoursite.com/product?ref=name.
- Страницы для печати, созданные вашей CMS, которые имеют точно такой же контент, как и ваши веб-страницы.
- Страницы, которые http до входа в систему и https после.
Примеры:
- Цитаты с других сайтов при использовании в модерации на вашей странице внутри кавычек. Они предпочтительно должны быть связаны с исходной ссылкой.
- Изображения с других сайтов или изображения повторяются на вашем собственном сайте (ах). (Это не считается дублирующимся контентом, так как поисковые системы не могут сканировать изображения).
- Инфографика делится с помощью кодов для вставки.
Нет такого понятия, как штраф за дублирование контента. У вас есть доказательства прямо из уст лошади от Google Вот а также Вот , Но это не означает, что проблема дублирования контента будет легкомысленной. Последствия дублирования контента на ваших веб-страницах - потеря трафика, просто потому, что вы «исключены из результатов поиска». Правильно, вы не проиндексированы и не оштрафованы, но дублированный контент просто не показывается пользователям в результатах поиска. В Google вы можете найти сообщение, подобное показанному ниже:

Если пользователь щелкнет ссылку, чтобы повторить поиск, он обнаружит пропущенные страницы с дублированным контентом. Однако вероятность того, что пользователь действительно щелкнет по этой ссылке, в основном равна нулю, поскольку сообщение отображается на последней странице поиска - да, на странице 8042 или на любом количестве страниц, которые может вернуть поиск. Кроме того, если у вас есть одна версия контента, зачем вам нужна повторная? Это один из способов, которым Google совершенствует пользовательский опыт своей поисковой системы, и это правильно. Итак, как это влияет на ваш сайт? Существует много способов, которыми ваш сайт может быть затронут тем, как Google обрабатывает дублирующийся контент:
- Потеря оригинального контента до пропущенных результатов . Если ваш оригинальный блог был распространен на многие сторонние веб-сайты без ссылки на ваш контент, есть большая вероятность, что ваш оригинальный контент будет пропущен и заменен их контентом. Это особенно верно, если сторонний сайт имеет более высокий PageRank, более высокое влияние и / или более качественные обратные ссылки, чем ваш сайт.
- Потеря времени на индексацию для ботов . При индексации вашего сайта боты поисковых систем обрабатывают каждую ссылку как уникальную и индексируют контент на каждой из них. Если у вас есть повторяющиеся ссылки из-за идентификаторов сеансов или по какой-либо из причин, упомянутых выше, боты тратят свое время на индексацию повторного контента, а не на индексацию другого уникального контента на вашем сайте.
- Многократные дублирующиеся ссылки означают разбавленный сок ссылок : если вы создаете ссылки, указывающие на страницу с несколькими URL-адресами, сок проходящих ссылок распределяется между ними. Если все страницы будут объединены в одну, сок ссылок также будет консолидирован, что может повысить поисковый рейтинг веб-страницы. Для получения дополнительной информации см. SEO Guide to Поток сока Link ,
- Потеря трафика . Очевидно, что если ваш контент не соответствует версии, выбранной Google для показа в результатах поиска, вы потеряете ценный трафик на ваш сайт.
Самый простой и логичный способ - скопировать и вставить фрагмент вашего контента в поиск Google и посмотреть, появляется ли какая-либо другая страница с точно таким же контентом. Есть и другие способы, и они заключаются в следующем:
1. Консоль поиска Google:
Дублированный контент не ограничивается контентом, присутствующим на веб-странице, но также может быть контентом, видимым в фрагментах поиска, таких как мета-заголовки и мета-описания. Дублирование такого содержимого можно легко обнаружить с помощью консоли поиска Google в разделе «Оптимизация»> «Улучшения HTML», как показано на снимке экрана выше.
2. Внешние инструменты:
Copyscape.com является отличным инструментом для проверки дублированного контента на вашем сайте. Это бесплатный инструмент, доступный как для Mac, так и для ПК.
3. «Сайт:» Оператор поиска:
Введите свой сайт в поиске, используя оператор поиска: site вместе с частью контента со страницы, следующим образом:
site: www.yoursite.com [часть контента скопирована с вашего сайта здесь]
Если вы видите сообщение от Google, в котором говорится о пропущенных результатах (как показано на первом снимке экрана в этом блоге), это означает, что на вашем сайте есть дублированный контент, присутствующий на сайте или за его пределами.
Итак, последний вопрос ...
Удаление дублированного контента с вашего сайта возможно, и стоит потратить время и усилия, чтобы сделать ваш сайт максимально удобным для поисковых систем. Об удалении дублирующегося контента с других сайтов, которые объединяют ваш оригинальный контент, следует заботиться так, как вы предпочитаете; либо отправив им вежливое электронное письмо, либо упоминание в их комментариях в блоге с указанием ссылки и ссылкой на ваш оригинальный контент.
Ниже приведены способы справиться с дублированием контента, созданного на вашем собственном сайте:
1. Rel = «канонический»:
Если вы используете систему управления контентом, синдицируете контент или у вас есть сайт электронной коммерции, легко получить несколько URL-адресов или доменов, указывающих на один и тот же контент. Чтобы бороться с этим, скажите поисковым системам, где они должны найти оригинал, используя тег rel = "canonical". Когда поисковая система видит эту аннотацию, она знает, что текущая страница является копией, и где найти канонический контент.
Как мне это сделать?
Начните с решения, какой URL вы хотите сделать каноническим. В общем, вы должны выбрать лучший оптимизированный URL как ваш канонический URL. Сделайте еще один шаг и настройте предпочитаемый домен в консоли поиска Google. Хорошим преимуществом установки предпочтительного домена является то, что поисковые системы будут учитывать это при сканировании ссылок на вашу страницу; ссылки на example.com передают сок ссылок на ваш предпочтительный домен www.example.com , То же самое касается других факторов индексации, таких как доверие и авторитет.
Чтобы правильно сообщить поисковой системе, что контент копируется с вашего канонического URL, поместите аннотацию rel = "canonical" в <head> вашей страницы. Это должно выглядеть так:
<link rel = "canonical" href = "<https://www.example.com>"
Если у вас есть версия документа, отличная от HTML (например, PDF, доступный для загрузки), вы можете включить каноническую ссылку в заголовок HTTP следующим образом: Ссылка: <https://www.example.com/document.html > ">; rel =" canonical "
Что может пойти не так?
Хотя тег rel = "canonical", по-видимому, достаточно прост для реализации, неправильное его использование может существенно повлиять на эффективность поиска. Существует несколько распространенных неправильных применений канонизации, которых вы должны избегать:
Все содержимое страницы разбито на первую страницу. Когда вы добавляете каноническую аннотацию к содержимому страницы, сопоставьте URL-адрес своей страницы 1 с URL-адресом своей канонической страницы 1, со страницы 2 до страницы 2 и т. Д. Мы рассмотрим это чуть позже.
Канонические URL-адреса, которые не совпадают на 100%: если ваш сайт использует относительные ссылки протокола, отключение http / https все равно приведет к тому, что поисковые системы увидят дублирующийся контент по этим двум адресам. Всегда делайте ваши предпочтительные URL 100% точными совпадениями.
Указание на канонические URL-адреса, которые возвращают ошибку 404: поисковые системы будут игнорировать теги, которые указывают на мертвую страницу.
Несколько канонических тегов: поисковые системы поддерживают только одну аннотацию rel = "canonical" на страницу. Вы можете получить несколько, когда веб-мастер скопирует шаблон страницы, который уже содержит rel = "canonical", или плагин автоматически вставит rel = "canonical". В случае нескольких канонических тегов, Google просто проигнорирует их все ,
2. Хрефланг
Введенный Google в 2011 году тег hreflang позволяет сообщать поисковой системе, что страница связана с другими страницами на разных языках и / или в разных регионах. Если ваш сайт https://example.com и у вас есть та же страница на испанском языке на [https://example.com/es[https://example.com/], используйте тег hreflang, чтобы сообщить поисковым системам, что они должны обслуживать эту страницу для испаноязычных поисковиков. ,
Важно отметить, что hreflang является фактором, а не директивой, в результатах поиска. Поэтому, если у вас есть страницы, которые слишком похожи (например, страницы на английском языке, ориентированные на США и Канаду), вы рискуете получить неправильный рейтинг версии для поискового запроса. Многоязычные сайты должны быть частью вашей общей маркетинговой стратегии.
Как мне это сделать?
Аннотация hreflang реализована в
раздел HTML-страницы. Для не-HTML страниц тег можно поместить в заголовок HTTP. Когда все сделано правильно, тег hreflang должен выглядеть так:
Вы должны включить ссылки на каждую версию вашей страницы. Если у вас есть английская, испанская и французская копии, поместите ссылки на все три страницы.
,
Если у вас две или более страниц на одном языке, но они предназначены для разных географических регионов (скажем, США, Канады и Великобритании), вы можете расширить переменную hreflang, включив код страны, например:
<link rel = "alternate" hreflang = "en-us" href = "<https://www.example.com>">
<link rel = "alternate" hreflang = "en-ca" href = "[https: //www.example..com/ca] (about: blank)">
<link rel = "alternate" hreflang = "en-gb" href = "<https://www.example.com/uk>">
Если у вас есть не HTML-страница на нескольких языках, разделите каждую аннотацию hreflang с помощью запятых следующим образом:
ссылка: << https://www.example.com/ >>; отн = «альтернативный»; hreflang = "EN-US",
ссылка: << https://www.example.com/> ca />; отн = «альтернативный»; hreflang = "ан-са",
ссылка: << https://www.example.com/> uk />; отн = «альтернативный»; hreflang = "ан-ГБ",
Существует также третий вариант реализации тегов hreflang: ваш XML карта сайта , Вместо того, чтобы добавлять разметку к своим страницам, включите версии своих URL на иностранных языках в свою карту сайта. Как и в других аннотациях, включите URL для каждого языка.
Что может пойти не так?
Распространенной проблемой при вставке аннотаций hreflang являются «Return Tag Errors». Эти ошибки происходят из аннотаций hreflang, которые не связаны друг с другом. Аннотации - это улица с двусторонним движением; если ваша английская страница ссылается на вашу страницу на немецком языке, ваша страница на немецком языке должна ссылаться на вашу страницу на английском языке. Возможно, самая распространенная ошибка возврата тега - это отсутствие ссылки на себя - вашей английской странице нужна ссылка на себя.
Чтобы проверить наличие ошибок тегов возврата, посмотрите данные международного таргетинга консоли поиска в разделе «Трафик поиска». Это скажет вам, сколько тегов hreflang было найдено Google и сколько есть ошибок.
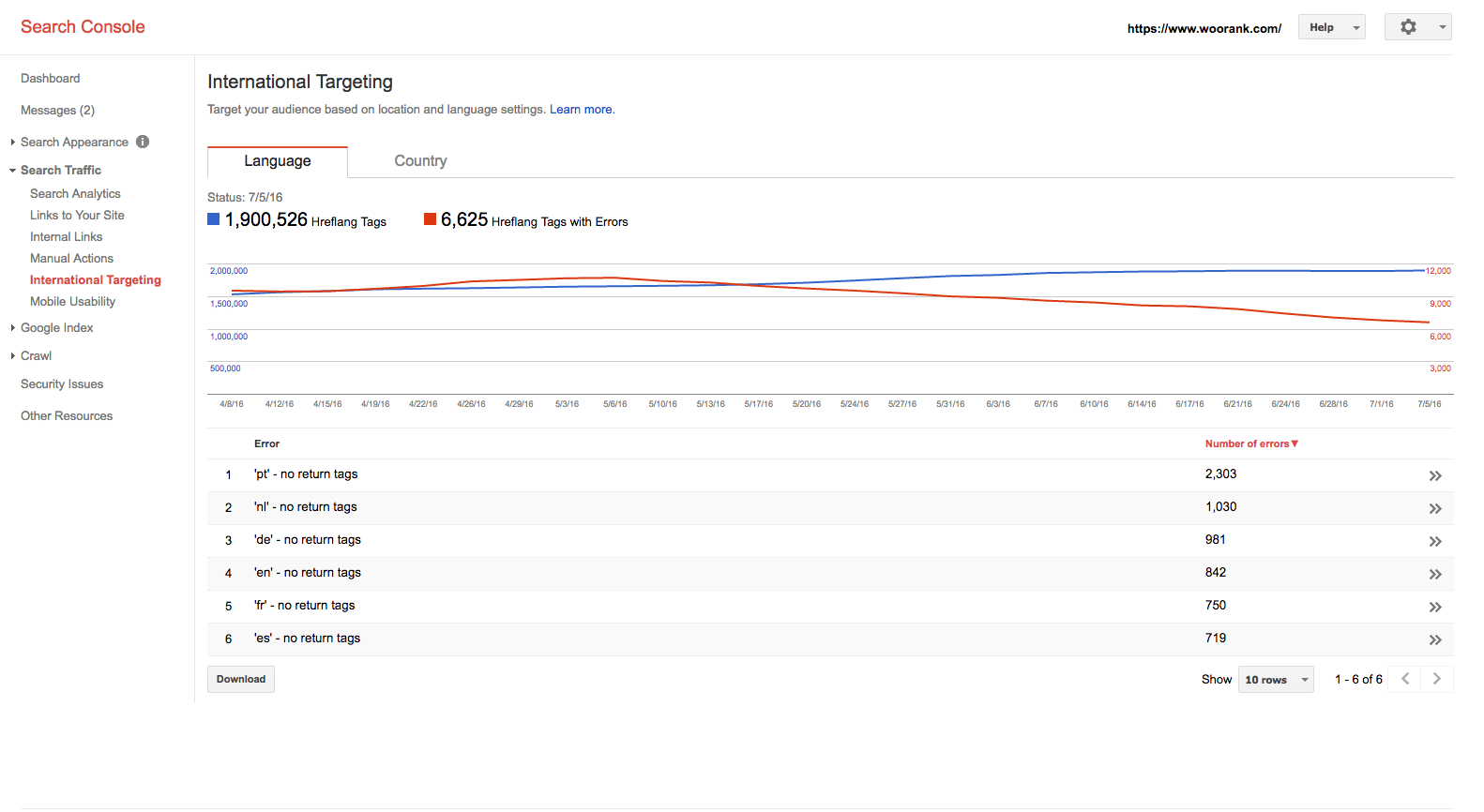
Еще одна распространенная проблема реализации аннотаций hreflang - это неправильные коды языка или страны. Значение hreflang должно быть в ISO 639-1 формат для языка и ISO 3166-1 Alpha 2 формат для страны. Использование «Великобритании» для Соединенного Королевства является наиболее распространенным преступником; в этой системе значение должно быть «gb» для Великобритании. Обратите внимание, что значение hreflang должно начинаться с кода языка, а таргетинг на регион ограничен странами - например, нельзя ориентироваться на Европейский Союз или Северную Америку.
3. 301 переадресация:
Вы можете использовать перенаправления 301 на дублирующихся страницах, которые генерируются автоматически и не нужны пользователю для просмотра. Добавление тегов rel = «canonical» к дублирующимся страницам делает страницу видимой для пользователей, в то время как перенаправления 301 указывают и роботам поисковой системы, и пользователям только на предпочитаемую страницу. Это должно быть сделано специально для URL домашней страницы от WWW URL до URL не-WWW или наоборот, в зависимости от того, какой URL используется чаще всего. Аналогично, если у вас есть дублированный контент на нескольких веб-сайтах с разными доменными именами, вы можете перенаправить страницы на один URL-адрес с помощью перенаправления 301. ПРИМЕЧАНИЕ. Перенаправления 301 являются постоянными, поэтому будьте осторожны при выборе предпочтительного URL-адреса.
Вы можете использовать мета-тег robots с атрибутами nofollow и noindex, если вам нужно, чтобы поисковая система не проиндексировала дублирующую страницу. Просто добавьте следующий код на дубликат страницы:
<meta name = ”robots” content = ”noindex”>
Есть еще один способ исключить дубликаты страниц из индексов поисковой системы, а именно запретить ссылки со специальными символами в файле robots.txt. Примечание: Google посоветовал не запрещать страницы на основе дублирующегося контента, используя robots.txt, потому что, если URL-адрес полностью заблокирован, есть вероятность, что роботы поисковых систем могут найти URL-адреса за пределами веб-сайта по ссылкам и могут рассматривать их как уникальные страницы. Это означает, что поисковые системы, вероятно, выберут эту страницу в качестве предпочтительной среди всех дубликатов, даже если это не было вашим намерением.
5. Консоль поиска Google:
Вы можете установить предпочтительные URL-адреса в своей учетной записи консоли поиска Google в разделе « Конфигурация»> «Дополнительные ссылки»> «Предпочитаемый домен» . Пройдя еще один шаг, вы можете настроить параметры URL-адреса для удаления дублирующихся страниц из индексации Google-бота. Эта опция также доступна в разделе «Конфигурация» в подразделе «Параметры URL», однако ее использование может привести к деиндексации важных страниц, если она не настроена должным образом, поэтому не рекомендуется, если вы не совсем уверены, как это сделать. Узнайте больше о параметрах URL в нашем блоге на Чистые URL для SEO и юзабилити ,
6. Отслеживание хеш-тегов:
Вместо использования параметров отслеживания в URL-адресах (которые создают дубликаты страниц с одинаковым содержимым) попробуйте использовать метод отслеживания хеш-тегов. Параметры отслеживания используются для отслеживания посещений с определенных сайтов на ваш сайт, например, с сайта маркетолога партнерской программы. Эти параметры обычно присутствуют после знака вопроса (?) В URL. С помощью метода хэш-тега мы удаляем знак вопроса и используем хэш-тег (#). Зачем? Ну, боты Google, как правило, игнорируют все, что присутствует после хеш-тега. Так, например, у вас могут быть дубликаты URL, такие как http://yoursite.com/product/ и http://yoursite.com/product/#utm_source=xyz. Когда вы используете хеш-тег, Google видит обе ссылки как http://yoursite.com/product/. Для этого используйте _setAllowAnchor метод, как показано Вот ,
7. Содержимое по конкретным доменам доменов верхнего уровня:
Когда у вас есть предприятия, разбросанные по всему миру, естественно иметь несколько доменов для каждого местоположения, и, скорее всего, невозможно создать уникальный контент для каждого из этих сайтов, если продукт / услуга одинаковы. Как вы справляетесь с дублированием контента в доменах вашей страны? Для начала перейдите в Консоль поиска Google> Конфигурация> Настройки в каждом из доменов, специфичных для страны, и выберите страну целевой аудитории для каждого сайта.
- Если возможно, используйте локальный сервер для каждого домена конкретной страны.
- Введите локальные адреса и номера телефонов на каждом из страновых сайтов.
- Используйте гео метатеги. Эти теги могут не использоваться Google, так как вы уже установили параметр целевых пользователей в консоли поиска Google, но они могут пригодиться, чтобы вторичные поисковые системы, такие как Bing, знали, что ваш сайт ориентирован на конкретную страну.
- Используйте <a href="https://support.google.com/webmasters/answer/189077?hl=en" target="_blank"> rel = «alternate» hreflang = «x» </a>, чтобы позволить Google-ботам узнать больше о ваших иностранных страницах с тем же содержанием и показать, какая страница должна быть возвращена для какой аудитории в результатах поиска.
Некоторые оптимизаторы могут предложить использовать rel = «canonical», чтобы справиться с междоменными дубликатами, но пока не ясно, является ли использование этого для перенаправления многодоменных страниц правильным решением, так как необходимо, чтобы сайты с геотаргетингом отображались в результатах поиска для соответствующих страновых поисковых запросов. На данный момент мы рекомендуем уточнить, что ваш контент имеет географическую ориентацию, чтобы поисковые системы знали, какой контент показывать какой аудитории, избегая путаницы.
8. Разбивка на страницы:
Если у вас есть контент со связанными компонентами, распределенными между несколькими страницами, и вы хотите отправлять пользователей на определенные страницы с помощью результатов поиска, используйте rel = «next» и rel = »prev», чтобы поисковые системы знали, что эти страницы являются частью последовательности. Узнайте больше о реализации этих атрибутов rel в блоге Google Webmaster Central на Нумерация страниц с rel = «next» и rel = «prev» , Существует еще один вид разбиения на страницы, когда речь идет о комментариях в блоге. Отключите разбиение на комментарии в своей CMS, иначе (на большинстве сайтов) будут созданы разные URL одного и того же контента.
Примечание. После того, как вы воспользовались этими стратегиями, чтобы избавиться от дублированного контента, не забудьте обновить свой файл Sitemap XML, удалив дублирующиеся URL-адреса и оставив только канонические URL-адреса, а затем повторно отправьте файл Sitemap в Google Search Console. Читайте наш руководство по XML Sitemaps для дополнительной информации.
Есть также несколько вещей, которые вы можете сделать, чтобы регулярно бороться с дублирующимся контентом на вашем сайте. Например, улучшите свою внутреннюю ссылку и сделайте ссылку на предпочтительные домены. По мере того, как будет найдено больше ссылок, указывающих на предпочтительные URL-адреса, поисковым системам будет легче судить, какая страница является предпочтительной. Кроме того, на сайтах электронной коммерции, когда у вас есть продукты, которые классифицированы по цветам, размерам или чему-либо еще, каждый раз, когда пользователь нажимает на размер или цвет, URL-адрес изменяется из-за параметра сортировки, и это создает дублированный контент. В таких случаях предоставьте возможность выбирать критерии выбора на той же странице, чтобы URL-адрес не изменялся.
Дайте нам знать в комментариях, если у вас есть какие-либо вопросы о дублировании контента на вашем сайте или если у вас есть какие-либо предложения по работе с дублирующимся контентом, которые не были упомянуты в этом блоге.
Что может пойти не так?Что может пойти не так?
Итак, сколько и о чем вам действительно нужно беспокоиться в отношении дублированного контента?
Com/product?
Com/category?
Com/product?
Кроме того, если у вас есть одна версия контента, зачем вам нужна повторная?
Итак, как это влияет на ваш сайт?
Как мне это сделать?
Как мне это сделать?