




Вы когда-нибудь задумывались, как результаты некоторых популярных инструментов исследования ключевых слов сопоставляются с информацией, которую предоставляет Google Search Console? В этой статье рассматривается сравнение данных из поисковой аналитики Google Search Console (GSC) с известными инструментами исследования ключевых слов и того, что вы можете извлечь из Google.
В качестве бонуса вы можете получить похожие результаты поиска, а также пользователи могут искать результаты в результатах поиска Google, используя код в конце этой статьи.
Эта статья не предназначена для научного анализа, так как содержит только данные с семи сайтов. Чтобы быть уверенным, мы собирали несколько всеобъемлющих данных: мы выбрали веб-сайты из США и Великобритании плюс разные вертикали.
Процедура
1. Начал с определения отраслей по отношению к различным вертикалям веб-сайтов.
Мы использовали Похожие категории определить группы и выбрать следующие категории:
- Искусство и развлечения.
- Автомобили и транспортные средства.
- Бизнес и промышленность.
- Дом и сад.
- Отдых и хобби.
- Покупка.
- Ссылка.
Мы извлекли анонимные данные из выборки наших веб-сайтов и смогли получить невидимые данные от специалистов по поисковой оптимизации (SEO). Аарон Дикс а также Даниэль Дженев , Поскольку этот первоначальный исследовательский анализ включал количественные и качественные компоненты, мы хотели потратить время на понимание процесса и нюансов, а не идти на уступки, необходимые для расширения анализа. Мы считаем, что этот анализ может привести к грубой методологии для внутренних оптимизаторов, чтобы сделать более обоснованное решение о том, какой инструмент лучше подходит их соответствующие вертикали.
2. Полученные данные GSC с веб-сайтов в каждой нише
Данные были получены из Google Search Console путем программирования и использования ноутбука Jupyter.
Записные книжки Jupyter - это веб-приложение с открытым исходным кодом, которое позволяет создавать и обмениваться документами, содержащими оперативный код, уравнения, визуализации и текст описания, для ежедневного извлечения данных на уровне веб-сайта из API-интерфейса Search Analytics, что обеспечивает гораздо большую степень детализации, чем в настоящее время доступно в Веб-интерфейс Google.
3. Собран рейтинг ключевых слов одной внутренней страницы для каждого сайта
Поскольку на домашних страницах, как правило, собирается много ключевых слов, которые могут иметь или не иметь тематического отношения к фактическому содержанию страницы, мы выбрали установленную и эффективную внутреннюю страницу, чтобы рейтинги с большей вероятностью относились к содержанию страницы. Это также более реалистично, поскольку пользователи, как правило, проводят исследования ключевых слов в контексте конкретных идей контента. 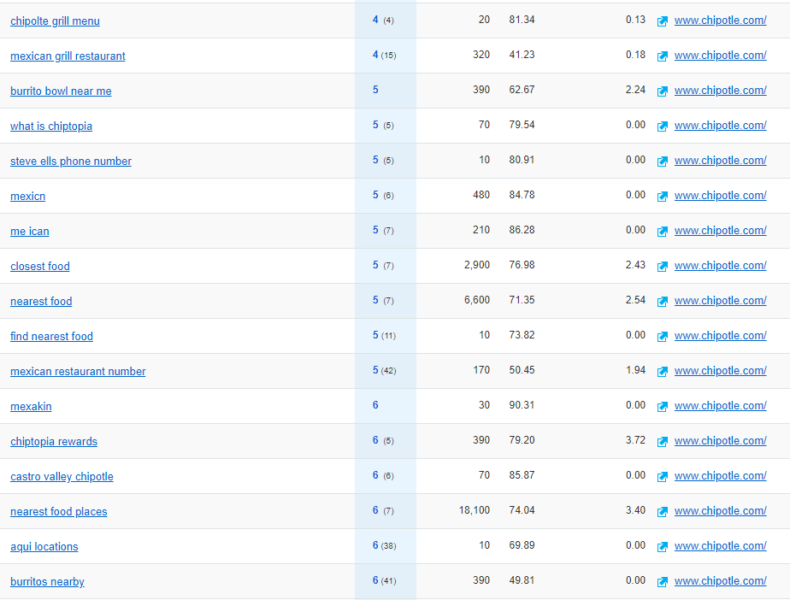
Приведенное выше изображение является примером ранжирования домашней страницы для различных запросов, связанных с бизнесом, но не имеющих прямого отношения к содержанию и цели страницы.
Мы удалили термины бренда и ограничили запросы консоли поиска Google результатами первой страницы.
Наконец, мы выбрали заголовок для каждой страницы. Фраза «главный термин» обычно используется для обозначения популярного ключевого слова с большим объемом поиска. Мы выбрали термины с относительно большим объемом поиска, но не с максимальным объемом поиска. Из запросов с наибольшим количеством показов мы выбрали тот, который лучше всего представлял страницу.
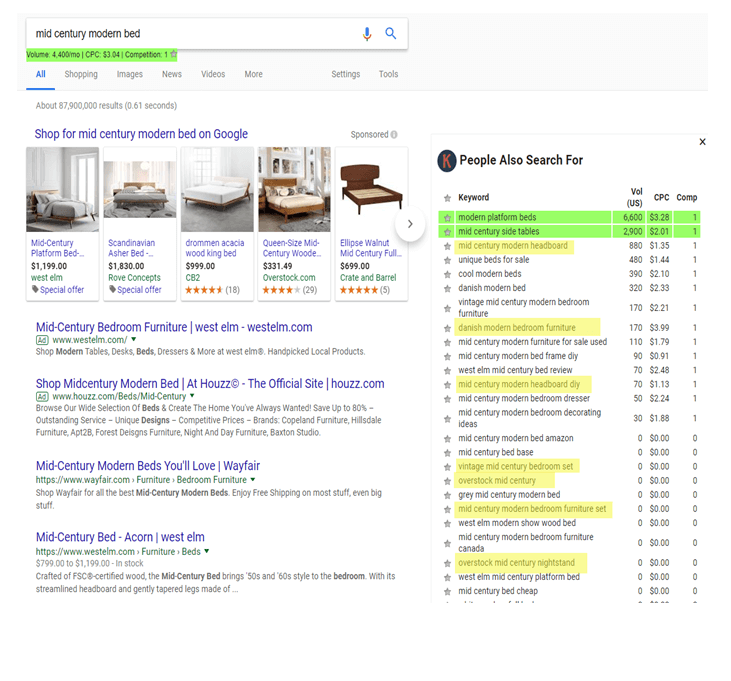
4. Проводил исследования ключевых слов в различных инструментах ключевых слов и искал заголовок
Затем мы использовали основной термин, выбранный на предыдущем шаге, для исследования ключевых слов в трех основных инструментах: Ahrefs, Moz и SEMrush.
Были использованы параметры «предложения по поиску» или «связанный поиск», и все возвращаемые запросы сохранялись независимо от того, указывал ли инструмент метрику того, как предложения были связаны с ключевым термином.
Ниже мы перечислили количество результатов по каждому инструменту. Кроме того, мы извлекли «люди также ищут» и «похожие поиски» из поисков Google для каждого ключевого термина (в зависимости от страны) и добавили количество результатов, чтобы дать базовый уровень того, что Google дает бесплатно.
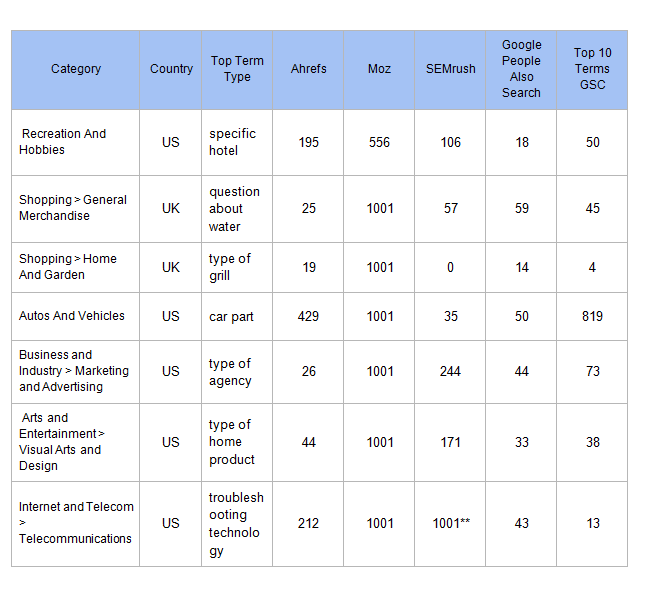
** Этот результат дал более 5000 результатов! Он был усечен до 1 001, что является максимально работоспособным и отсортировано по убыванию объема.
Мы составили среднее количество ключевых слов, возвращаемых на инструмент:
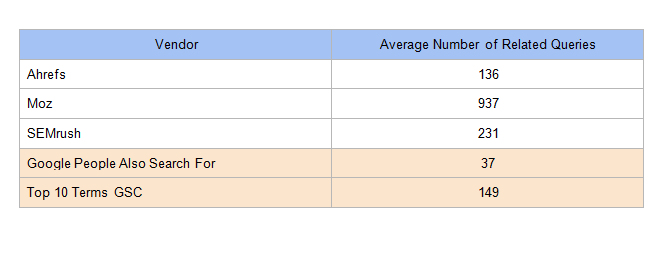
5. Обработал данные
Затем мы обработали запросы для каждого источника и веб-сайта, используя некоторые методы языковой обработки для преобразования слов в их корневые формы (например, «работает», чтобы «выполнить»), удалили общие слова, такие как «a», «the» и « и »расширили сокращения, а затем отсортировали слова.
Например, этот процесс преобразует «SEO агентства в Роли» в «агентство Raleigh SEO». Обычно это сохраняет важные слова и приводит их в порядок, чтобы мы могли сравнивать и удалять похожие запросы.
Затем мы создали процент, разделив количество уникальных терминов на общее количество терминов, возвращаемых инструментом. Это должно сказать нам, сколько избыточности в инструментах.
К сожалению, это не учитывает орфографические ошибки, что также может быть проблематично в инструментах исследования ключевых слов, поскольку они добавляют дополнительную погрешность (ненужные, нежелательные запросы) к результатам. Много лет назад на страницах веб-сайта можно было указывать типичные ошибки в написании терминов. Сегодня поисковые системы действительно хорошо понимают, что вы напечатали, даже если они написаны с ошибками.
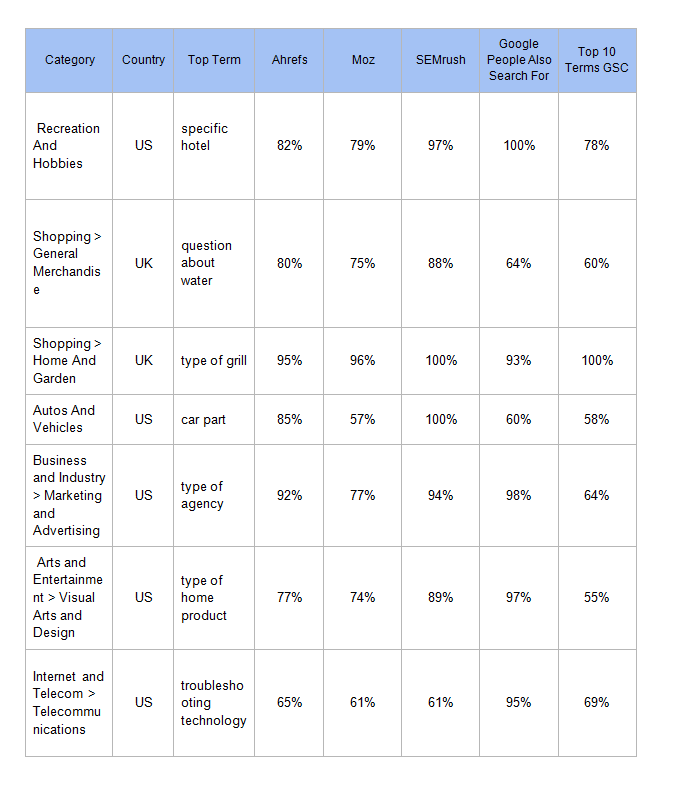
В приведенной ниже таблице SEMrush имел самый высокий процент уникальных запросов в своих поисковых подсказках.
Это важно, потому что, если 1000 ключевых слов уникальны только на 70 процентов, это означает, что 300 ключевых слов в основном не имеют уникального значения для выполняемой вами задачи.
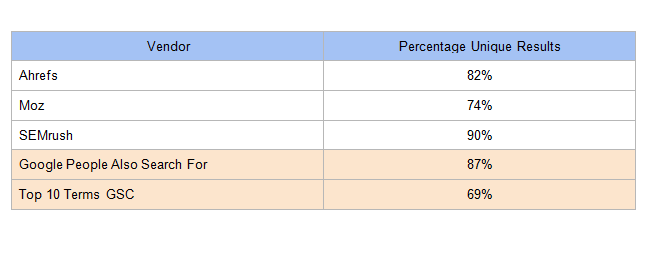
Далее мы хотели посмотреть, насколько хорошо различные инструменты находят запросы, используемые для поиска этих рабочих страниц. Мы взяли ранее уникальные, нормализованные фразы запросов и изучили процент GSC-запросов, которые инструменты имели в своих результатах.
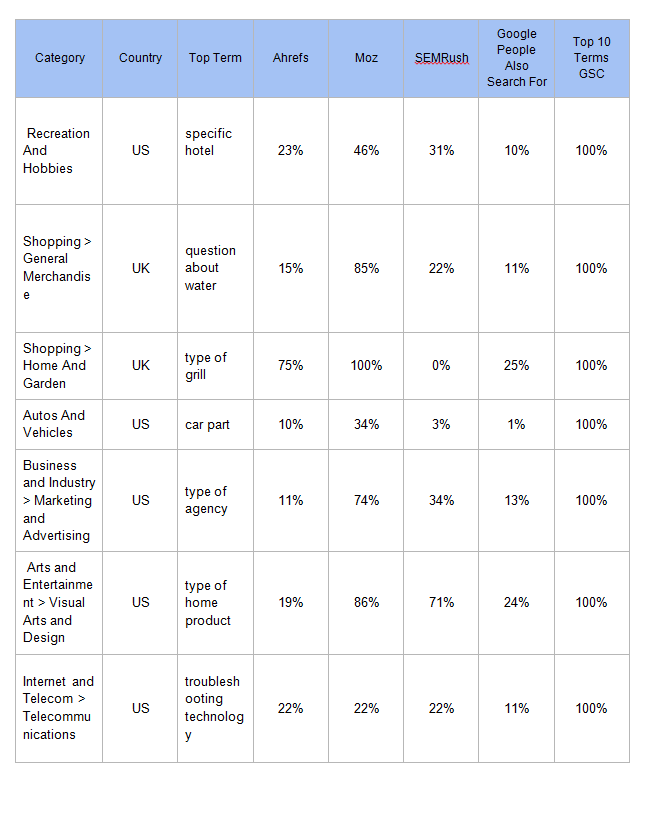
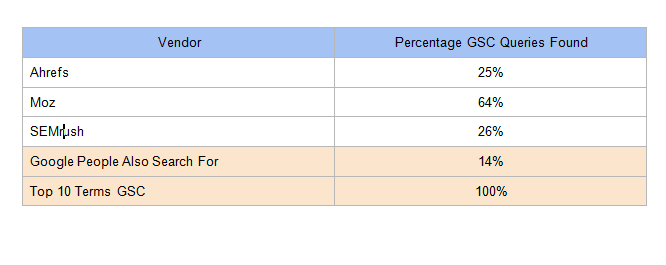
На приведенной ниже диаграмме обратите внимание на среднее покрытие GSC для каждого инструмента и то, что Moz здесь выше, скорее всего, потому что он дал 1000 результатов для большинства основных условий. Все инструменты работали лучше, чем связанные запросы, вырезанные из Google (используйте код в конце статьи, чтобы сделать то же самое).
Попасть в векторное пространство
После выполнения предыдущего анализа мы решили преобразовать нормализованные фразы запроса в векторное пространство, чтобы визуально изучить различия в различных инструментах.
Присвоение векторному пространству использует так называемые предварительно обученные векторы слов, которые уменьшены в размерности (координаты x и y) с использованием библиотеки Python, называемой t-распределенным стохастическим встраиванием соседей (TSNE). Не волнуйтесь, если вы не знакомы с этим; как правило, векторы слов - это слова, преобразованные в числа таким образом, что числа представляют внутреннюю семантику ключевых слов.
Преобразование слов в числа помогает нам обрабатывать, анализировать и составлять слова. Когда семантические значения нанесены на координатную плоскость, мы получаем четкое понимание как связаны различные ключевые слова , Точки, сгруппированные вместе, будут более семантически связаны, в то время как точки, удаленные друг от друга, будут менее связанными.
Покупка
Это пример, когда Moz возвращает 1000 результатов, но количество запросов и вариации ключевых слов в поисковике очень малы. Скорее всего, это вызвано тем, что Моз семантически сопоставляет конкретные слова, а не пытается сопоставить значение фразы. Мы попросили Moz's Russ Jones лучше понять, как Moz находит похожие фразы:
«Моз использует много разных методов для поиска связанных терминов. Мы используем один алгоритм, который находит ключевые слова с подобными страницами, ранжирующими их, мы используем другой алгоритм ML, который разбивает фразу на составные слова и находит комбинации связанных слов, производя связанные фразы, и т. Д. Каждый из них может быть полезен для различных целей, в зависимости от о том, хотите ли вы очень близкие или косвенные темы. Вы хотите улучшить свой рейтинг по ключевому слову или найти достаточно четкие ключевые слова, о которых все еще связаны? Результаты, полученные Moz Explorer, являются нашей попыткой достичь этого баланса ».
В Moz есть хорошая мера релевантности, а также фильтр для тонкой настройки соответствия ключевых слов. Для этого анализа мы просто использовали настройки по умолчанию:
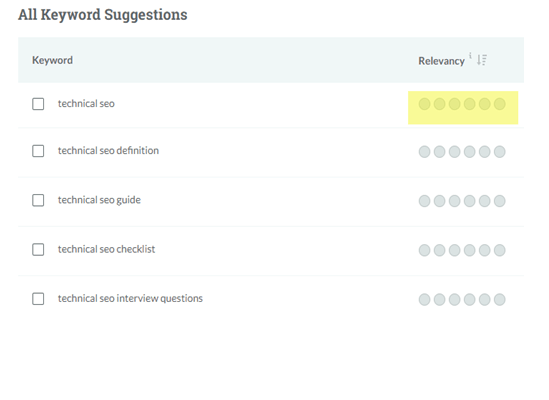
На изображении ниже график запросов показывает, что возвращает каждый поставщик ключевых слов, преобразованный в координатную плоскость. Положение и группировки дают некоторое понимание того, как связаны ключевые слова.
В этом примере Moz (оранжевый) создает значительный объем различных ключевых слов, в то время как другие инструменты выбрали гораздо меньше (Ahrefs в зеленом), но больше связаны с начальной темой:
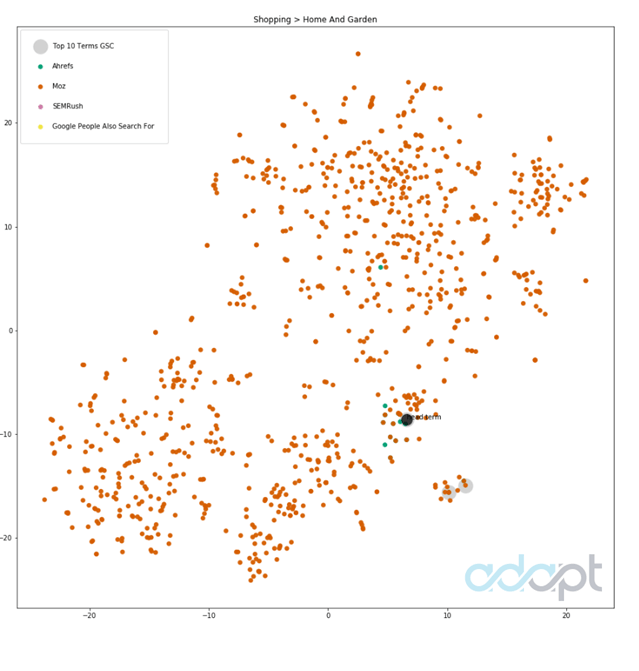
Автомобили и транспортные средства
Это весело. Вы можете видеть, что Моз и Арефс довольно неплохо освещали этот объемный термин. Моз выиграл, сопоставив 34 процента фактических условий из Google Search Console. У Моза было вдвое больше результатов (почти по умолчанию), чем у Арефа.
SEMrush отстает здесь с 35 запросами по теме с большим количеством полезного разнообразия.
Большие серые точки представляют больше основа истины Запросы из консоли поиска Google. Другие цвета - это различные используемые инструменты. Серые точки без наложенного цвета - это запросы, которые не совпадают с различными инструментами.
Интернет и телеком
Этот график интересен тем, что SEMrush подскочил почти до 5000 результатов, из диапазона 50-200 в других результатах. Вы также можете увидеть (в нижней части), что было много терминов за пределами того, за что эта страница имела тенденцию ранжироваться, или которые были излишними по сравнению с тем, что необходимо для понимания пользовательских запросов для новой страницы:
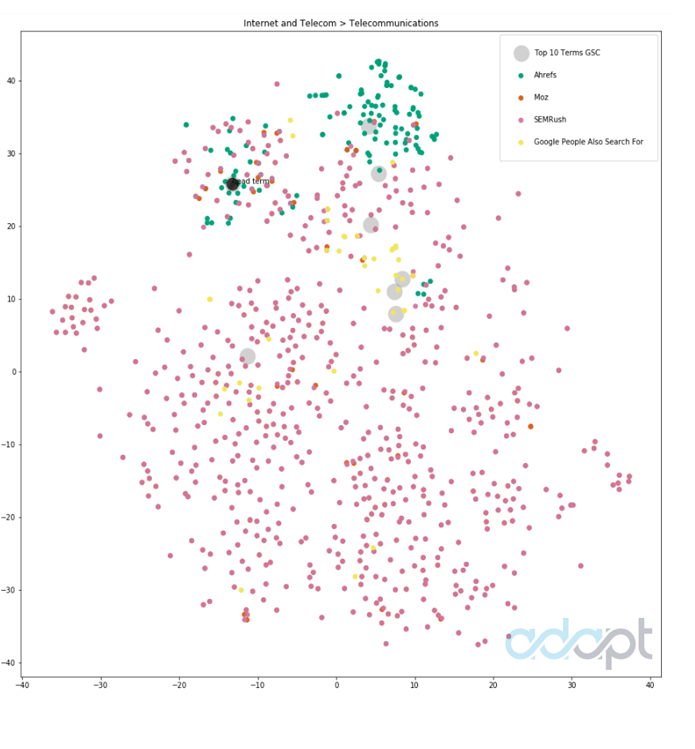
Большинство инструментов сгруппированы несколько ближе к главному термину, хотя вы можете видеть, что SEMrush (пурпурно-розовый) дал большое количество потенциально более несвязанных точек, даже несмотря на то, что Google People Также Поиск был найден в определенных группах.
Общие товары
Вот пример инструмента подсказки ключевых слов, который находит интересную группу терминов (группы, обозначенные черными кружками), для которых в данный момент страница не имеет рейтинга. Анализируя данные, мы обнаружили, что группировка справа имеет смысл для этой страницы:
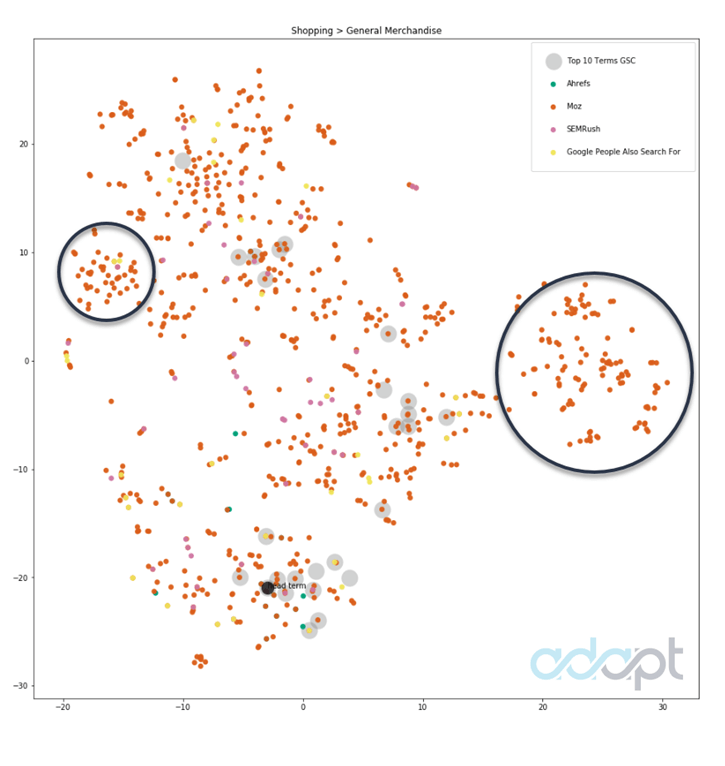
Два черных кружка помогают визуализировать возможность поиска групп связанных запросов при построении текста таким способом.
Анализ
Специалисты по поисковой оптимизации, имеющие опыт исследования ключевых слов, знают, что нет единого инструмента, который бы управлял ими всеми. В зависимости от данных, которые вам нужны, вам может понадобиться несколько инструментов, чтобы получить то, что вам нужно.
Ниже приведены мои общие впечатления от каждого инструмента после обзора, качественно:
- Данные запроса и цифры из нашего анализа уникальности результатов.
- Вероятность нахождения терминов, которые реальные пользователи используют для поиска исполняющих страниц.
Мос
Моз, кажется, имеет впечатляющие цифры с точки зрения необработанных результатов, но мы обнаружили, что в нескольких случаях общее качество и актуальность результатов отсутствовали.
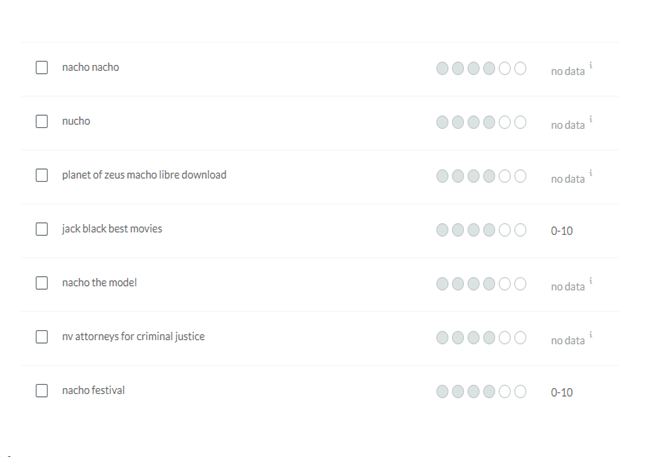
Даже играя с оценками релевантности, он быстро пошел по касательным, предоставляя запросы, которые никоим образом не были связаны с моим ключевым термином (см. Предложения Moz для «Nacho Libre» на изображении выше).
С учетом вышесказанного, Moz очень полезен из-за его всестороннего охвата, особенно для SEO, работающих в небольших или новых вертикалях. Во многих случаях чрезвычайно трудно найти ключевые слова для новых актуальных тем, поэтому больше ключевых слов определенно лучше.
В среднем 64-процентный охват реальных пользовательских данных из GSC для выбранных доменов был очень впечатляющим. Это также говорит о том, что, хотя результаты Moz могут привести к провалу в кроличьих ямах, они, как правило, тоже получают правильные результаты. Они обменяли потерю верности на всесторонность.
Ahrefs
Ahrefs был моим фаворитом с точки зрения качества благодаря их хорошему сочетанию комплексных результатов с минимальным количеством явно не связанных запросов.
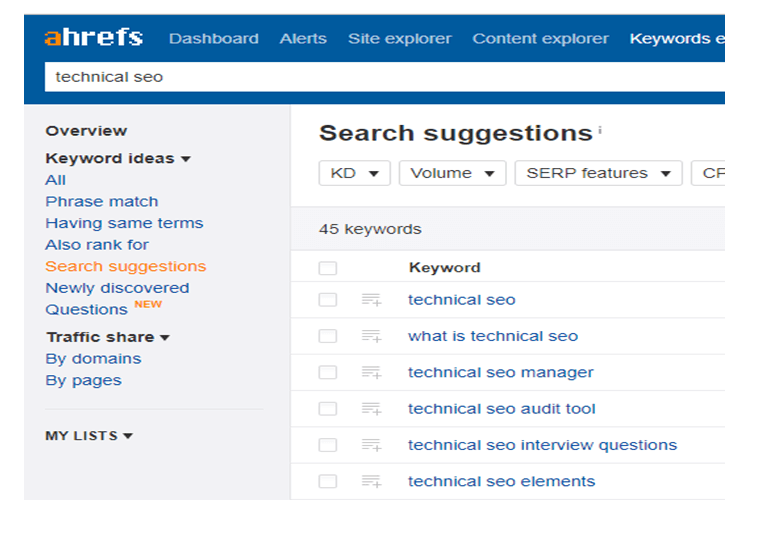
У него было наименьшее количество усредненных результатов по ключевым словам на каждого поставщика, но это на самом деле вводит в заблуждение из-за большого выброса SEMrush. Через различные поиски он имел тенденцию возвращать хороший набор терминов без большого количества беспорядка, чтобы пробираться через.
Самым впечатляющим для меня был особый тип нишевого гриля, который разделял имя с популярным местоположением. Результаты от Ahrefs остались точными, в то время как SEMrush ничего не возвратил, и Моз пошел по касательным со многими ключевыми словами, связанными с популярным местоположением.
Представитель компании Ahrefs пояснил мне, что их инструмент «поисковые подсказки» использует данные из Google Autosuggest. В настоящее время у них нет действительной системы рекомендаций, как у Моза. Использование данных «А также ранги для» и «Наличие одинаковых терминов» от Ahrefs позволило бы сопоставить их с количеством ключевых слов, возвращаемых другими инструментами.
SEMrush
SEMrush в целом предлагал отличное качество, при этом 90 процентов ключевых слов были уникальными. Он также был на одном уровне с Ahrefs с точки зрения соответствия запросов из GSC.
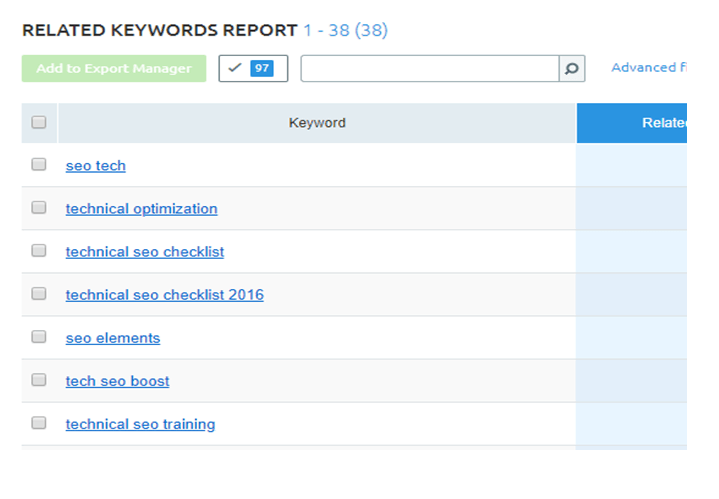
Это было, однако, самым противоречивым с точки зрения количества возвращенных результатов. Он дал более 1000 ключевых слов (на самом деле 5000) для Интернета и телекоммуникаций> Телекоммуникации, но охватил только 22% запросов в GSC. Для другого результата это был единственный, который не возвращал связанные ключевые слова. Это очень маленький набор данных, поэтому очевидно, что это были аномалии.
Google: люди также ищут / похожие запросы
Эти результаты были чрезвычайно интересны, потому что они имели тенденцию более близко соответствовать типам запросов, которые пользователи будут делать, находясь в определенном состоянии покупки, в отличие от тех, которые конкретно относятся к конкретной фразе. 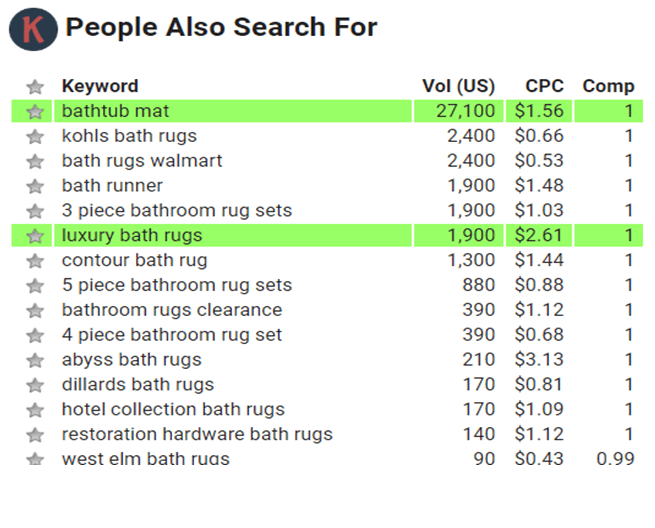
Например, поиск «[термин] занавески для душа» вернул «[термин] сиденья для унитаза».
Они не связаны с семантической точки зрения, но они оба имеют отношение к тому, кто переделывает свою ванную, предполагая, что сходство основано на намерении пользователя, а не на самих ключевых словах.
Кроме того, поскольку данные «люди также ищут» привязаны к отдельным результатам на страницах результатов поисковой системы Google (SERPs), трудно сказать, относятся ли термины к поисковому запросу или работают больше как ссылки на сайты, которые более отношение к отдельной странице.
Код используется
когда вошел в консоль Javascript Google Chrome на странице результатов поиска Google следующие данные выведут на страницу данные «Люди также ищут» и «Связанные поиски», если они существуют.
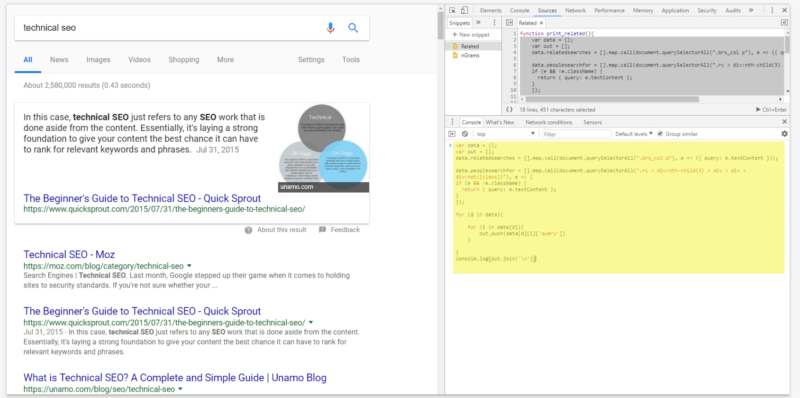
Кроме того, есть дополнение для Chrome, которое называется Ключевые слова везде который выставит эти термины в результатах поиска, как показано на нескольких снимках экрана SERP по всей статье.
Заключение
Особенно для внутренних маркетологов важно понять, какие инструменты обычно имеют данные, наиболее соответствующие вашей вертикали. В этом анализе мы показали некоторые преимущества и недостатки нескольких популярных инструментов по небольшой выборке тем. Мы надеялись предоставить подход, который мог бы сформировать основу вашего собственного анализа или для дальнейшего улучшения, и дать SEO-специалистам более практичный способ выбора исследовательского инструмента.
Инструменты исследования ключевых слов постоянно развиваются и добавляют новые найденные запросы с использованием данные о кликах и другие источники данных. Утилита в этих инструментах основывается исключительно на их способности помочь нам более кратко понять, как лучше позиционировать наш контент в соответствии с реальным интересом пользователя, а не на необработанном количестве возвращаемых ключевых слов. Не просто используйте то, что всегда использовалось. Проверьте различные инструменты и оцените их полезность для себя.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,